Exploring Weak-Strong Model Dynamics for Robustness Against Dataset Artifacts in MultiNLI
Team: Emmanuel Rajapandian
Resources: [Code]
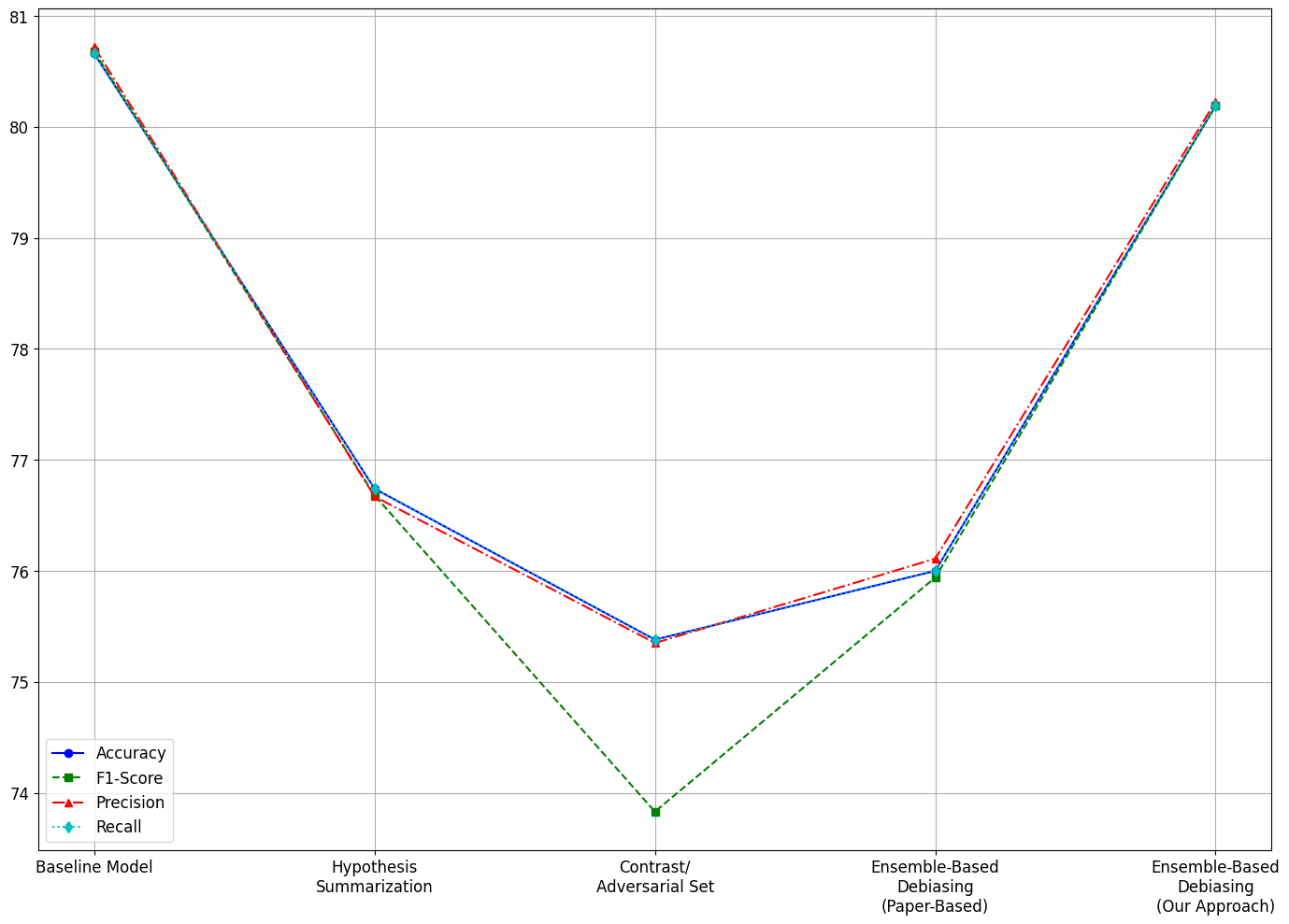
Summary: In this project, I investigate dataset artifacts in NLP tasks, particularly in the MultiNLI dataset, which often lead models to rely on spurious correlations instead of genuine semantic understanding. By fine-tuning the ELECTRA-small model, the research achieved a baseline accuracy of 80.66%. To enhance robustness, the study employed contrast sets and synthetically generated adversarial examples to probe model vulnerabilities. A weak-strong model ensemble framework was introduced, where the weak model captured superficial artifacts, and the strong model learned residuals to focus on deeper semantic patterns. Combining logits from both models during inference improved overall accuracy to 80.19% while maintaining robustness against artifacts. Additional techniques like hypothesis summarization and adversarial training further refined performance, particularly for challenging genres like “slate.” The findings emphasize the importance of targeted interventions to improve generalization and robustness in NLP systems.
My contribution: Sole contributor.